
Vous avez passé des mois, voire des années, à rédiger votre thèse. Chaque mot a été pesé, chaque référence vérifiée. Mais savez-vous ce que dit réellement votre fichier PDF final ? Bien au-delà du texte visible, votre document transporte une cargaison invisible : des dates de création précises, l'historique complet de vos révisions, le nom de votre ordinateur, et parfois même des commentaires critiques laissés par votre directeur de recherche. Pour un examen à double aveugle ou une soumission confidentielle, ces fuites peuvent être fatales.
Ce n'est pas un problème théorique. Dans le monde juridique, la négligence concernant les métadonnées est l'ensemble des informations cachées dans un fichier numérique qui révèlent son historique et ses propriétés techniques est devenue une source majeure de poursuites pour violation de la confidentialité. Les mêmes règles s'appliquent aux universités. Avant de cliquer sur « Envoyer », il est impératif de purger ces données sensibles. Voici comment procéder méthodiquement pour garantir que seule votre recherche soit évaluée, et rien d'autre.
Comprendre ce qui se cache dans votre PDF
Un fichier PDF n'est pas une simple image statique ; c'est un conteneur complexe. Lorsque vous exportez un document depuis un traitement de texte, le convertisseur copie souvent les propriétés du document source vers le fichier cible. Selon les guides techniques établis par les tribunaux américains, les métadonnées typiques incluent :
- L'auteur et l'éditeur : Votre nom complet peut apparaître plusieurs fois, y compris dans des champs techniques comme "Last Modified By".
- L'historique de révision : Le nombre total de modifications, le temps total de rédaction (en minutes), et parfois même le contenu des changements acceptés ou rejetés si la fonction « Suivi des modifications » n'a pas été correctement fermée.
- Les chemins d'accès : Des fragments d'URL internes révélant le nom de votre département, votre serveur universitaire ou votre dossier personnel cloud.
- Le créateur technique : L'application utilisée (par exemple, « Microsoft Word 16.0 » ou « LaTeX with pdfTeX »).
La particularité technique cruciale à retenir est qu'un PDF possède deux systèmes de stockage parallèles : l'ancien dictionnaire Info et le plus récent flux XMP. Un nettoyeur naïf qui ne supprime que l'un des deux laisse l'autre intact, exposant toujours vos données. Une solution efficace doit traiter les deux couches simultanément sans altérer le rendu visuel du document.
Étape 1 : Nettoyer la source (Microsoft Word)
La plupart des thèses sont rédigées dans Microsoft Word est un logiciel de traitement de texte dominant dans le milieu académique pour la rédaction de documents longs. C'est ici que naissent la majorité des traces indésirables. Ne comptez pas uniquement sur les outils PDF pour corriger ce qui vient de Word ; le nettoyage en amont est plus sûr.
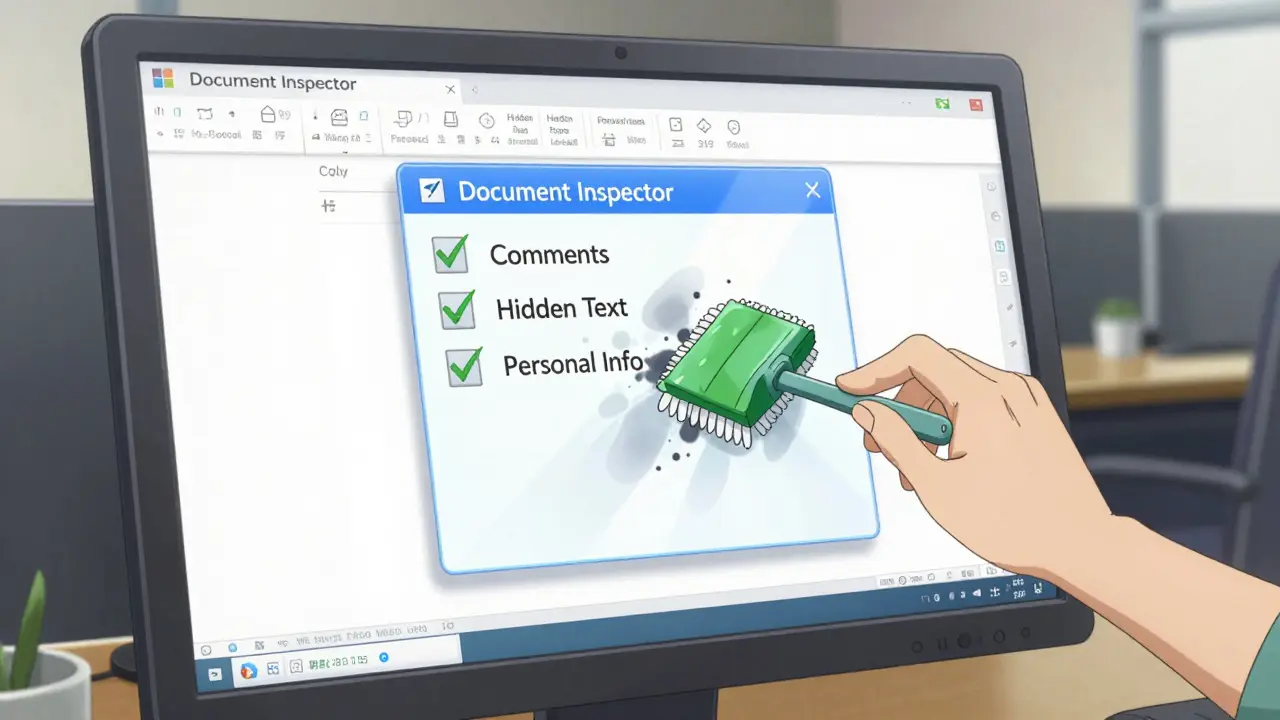
Avant toute conversion, utilisez l'outil intégré appelé « Inspecteur de documents ». Voici la procédure exacte :
- Ouvrez votre version finale de la thèse.
- Allez dans Fichier > Informations.
- Cliquez sur Vérifier le document puis sélectionnez Inspecter le document.
- Dans la fenêtre qui apparaît, assurez-vous que toutes les cases sont cochées, notamment « Propriétés du document et informations personnelles », « Commentaires », « Révisions » et « Texte masqué ».
- Cliquez sur Inspecter, puis sur Tout supprimer pour chaque catégorie identifiée.
Attention : cette action accepte automatiquement toutes les modifications suivies. Si vous souhaitez conserver un historique pour vos propres archives, faites-le sur une copie distincte (« Copie de travail ») et non sur le fichier destiné à la soumission. Vérifiez également les « Propriétés avancées » pour effacer manuellement le champ « Société » ou « Organisation » qui pourrait contenir le nom de votre université, nuisant ainsi à l'anonymat lors d'un examen à l'aveugle.
Étape 2 : Exporter proprement vers le format PDF
Une fois le fichier Word nettoyé, passez à l'exportation. Évitez les méthodes obsolètes comme l'impression via un pilote virtuel générique, qui peuvent ajouter leurs propres empreintes logicielles inutiles.
Utilisez la fonction native de Word : Fichier > Enregistrer sous > PDF. Cochez l'option « Optimiser pour : Taille minimale (publication en ligne) » si nécessaire, mais surtout, assurez-vous que l'option « Créer des signets en utilisant : Titres » est activée pour la navigation, tout en gardant à l'esprit que cela structure le document sans exposer de nouvelles données personnelles. À ce stade, votre fichier contient encore les métadonnées de base (Titre, Auteur) copiées depuis Word. Il faut maintenant vérifier et affiner ces dernières directement dans le PDF.
Étape 3 : Purger les métadonnées résiduelles du PDF
Même après un nettoyage soigné de Word, des traces subsistent. Vous avez deux options principales selon vos ressources : utiliser un logiciel professionnel installé ou un outil web sécurisé.
Option A : Adobe Acrobat Pro (Standard industriel)
Si votre université fournit une licence Adobe Acrobat Pro est le logiciel de référence pour la manipulation avancée de fichiers PDF, c'est l'outil le plus complet. La fonctionnalité clé se trouve sous l'onglet Outils > Protéger et optimiser > Supprimer les informations masquées. Cet outil scanne le fichier pour trouver non seulement les métadonnées, mais aussi les calques superposés, les fichiers joints cachés et les annotations invisibles.
Cependant, Acrobat est payant, lourd à installer, et nécessite souvent une connexion internet pour la validation de licence. De plus, certaines versions antérieures pouvaient envoyer des télémétries mineures, ce qui pose question pour des documents ultra-sensibles.
Option B : Nettoyage local et privé avec Metadata Remover
Pour ceux qui cherchent une alternative rapide, gratuite et respectueuse de la vie privée, l'outil Metadata Remover de Vaulternal offre une approche différente. Contrairement à la plupart des services en ligne qui téléchargent votre fichier sur un serveur distant pour le traiter - un risque inacceptable pour une thèse non publiée - cet outil fonctionne entièrement dans votre navigateur.
Le principe technique repose sur WebAssembly et JavaScript côté client. Cela signifie que votre fichier PDF ne quitte jamais votre appareil. Aucune donnée n'est envoyée à un serveur tiers. Vous pouvez vérifier cela vous-même en ouvrant l'onglet « Réseau » de votre navigateur pendant l'utilisation : aucun trafic sortant lié au fichier ne sera détecté. L'outil supprime simultanément le dictionnaire Info et le flux XMP, garantissant un nettoyage complet sans modifier le rendu pixel par pixel de votre document. Idéal pour valider rapidement l'absence de fuites avant la soumission finale.
Gérer l'examen à double aveugle
De nombreuses universités exigent un processus d'évaluation anonyme. Dans ce cas, la suppression des métadonnées n'est pas suffisante ; il faut les remplacer par des valeurs neutres.
Créez deux versions de votre PDF :
- Version anonyme : Supprimez le champ « Auteur » ou remplacez-le par « Candidat Anonyme ». Effacez les mots-clés contenant votre nom. Assurez-vous que l'en-tête et le pied de page ne contiennent aucune référence à votre identité ou à votre laboratoire.
- Version archivée : Conservez les métadonnées complètes (Auteur, Titre officiel, Mots-clés précis) pour le dépôt institutionnel futur. Ces données sont essentielles pour la découvrabilité de votre recherche dans les bases bibliographiques.
N'oubliez pas de vérifier les images intégrées. Si vous avez inséré des captures d'écran de logiciels ou des graphiques générés localement, celles-ci peuvent contenir des métadonnées EXIF révélant l'appareil photo ou le logiciel utilisé. Utilisez un outil de nettoyage d'images séparé si nécessaire, ou régénérez les graphiques depuis zéro dans un environnement éphémère.

Pièges courants à éviter absolument
La hâte est l'ennemie de la confidentialité. Voici les erreurs fréquentes commises par les doctorants :
- Régénérer le PDF depuis un fichier sale : Si vous nettoyez votre PDF, puis que vous modifiez le fichier Word source et réexportez, toutes les métadonnées supprimées reviendront. Travaillez toujours sur une copie finale figée.
- Oublier les pièces jointes : Certains étudiants ajoutent leurs jeux de données bruts ou leurs scripts de code en tant que fichiers attachés dans le PDF. Ces fichiers annexes ont leurs propres métadonnées et doivent être retirés ou nettoyés indépendamment.
- Confondre anonymat et suppression : Supprimer le nom de l'auteur ne suffit pas si le résumé mentionne « Mes travaux précédents sur... [Nom] ». Relisez le contenu textuel avec les yeux d'un examinateur externe.
- Ignorer les hyperliens internes : Un lien hypertexte pointant vers `C:/Users/JeanDupont/Documents/These/Brouillon.docx` est une fuite massive. Convertissez tous les liens internes en liens relatifs ou supprimez-les.
Vérification finale : la méthode du miroir
Avant de soumettre, ouvrez votre PDF final dans un visualiseur neutre (comme le lecteur intégré à votre navigateur web) et inspectez les propriétés. Sur Chrome ou Firefox, faites un clic droit > Propriétés ou utilisez l'extension appropriée. Vous devriez voir des champs vides ou génériques pour l'auteur et le créateur, sauf indication contraire de votre université.
Si vous voulez aller plus loin, certains outils permettent d'exporter les métadonnées supprimées en format JSON. Cette trace sert de preuve de nettoyage, utile si votre université demande une attestation de conformité aux normes de confidentialité. En suivant rigoureusement ces étapes, vous protégez non seulement votre vie privée, mais aussi l'intégrité scientifique de votre travail, en assurant qu'il soit jugé uniquement sur son mérite intellectuel.
Est-ce que supprimer les métadonnées rend mon PDF illisible ?
Non. Les métadonnées sont des informations techniques stockées séparément du contenu visuel. Leur suppression n'affecte ni le texte, ni les images, ni la mise en page. Le fichier reste parfaitement lisible et imprimable, exactement comme avant.
Dois-je nettoyer les métadonnées si je soumets ma thèse à ma propre université ?
Oui, absolument. Même si l'université connaît votre identité, les métadonnées peuvent contenir des chemins d'accès internes, des noms de serveurs privés ou des commentaires confidentiels de vos directeurs. De plus, une fois publiée, votre thèse sera accessible publiquement sur Internet. Il vaut mieux contrôler dès maintenant ce qui devient public.
La fonction « Inspecter le document » de Word est-elle suffisante ?
C'est une excellente première étape, mais elle ne garantit pas un PDF vierge. Lors de la conversion Word vers PDF, de nouvelles métadonnées techniques (créateur, producteur, date d'export) sont ajoutées. Il est recommandé de vérifier le fichier PDF final avec un outil dédié pour s'assurer qu'aucune trace n'a filtré à travers.
Quels sont les risques concrets de ne pas nettoyer les métadonnées ?
Les risques incluent la divulgation involontaire de votre identité lors d'un examen à l'aveugle (ce qui peut invalider le processus), la révélation de collaborateurs non listés, ou l'exposition de données sensibles relatives à votre infrastructure informatique universitaire. Dans le pire des cas, cela peut compromettre la confidentialité de recherches non publiées.
Existe-t-il des outils gratuits pour nettoyer les métadonnées PDF ?
Oui. Outre les fonctions intégrées à Adobe Acrobat (payant) et Word, il existe des solutions web gratuites comme Metadata Remover de Vaulternal. L'avantage majeur de ces outils spécifiques est qu'ils traitent le fichier localement dans votre navigateur, évitant tout téléchargement sur un serveur tiers, ce qui est crucial pour la confidentialité.





